ブラウザの仕組み
はじめに
普段使用しているツールである、ブラウザ。
最も複雑なアプリケーションの一つと言われるようになりました。
開発者である以上、ブラウザの仕組みを知っといても良いと思い、まとめてみました。
ブラウザは、インターネットを介してWebサーバーに接続し、HTML、CSS、JavaScript(以下、JS)ファイルを取得し画面に表示します。
ブラウザの主要コンポーネント
ブラウザは以下の主要なコンポーネントで構成されています。
- ユーザーインターフェース(UI)
- アドレスバー、戻るボタンなど。
- ユーザーが直接操作する部分。
- ブラウザエンジン
- UIとレンダリングエンジンを繋ぐ橋渡し役。
- リクエストやコマンドを正しいモジュールに転送する。
- レンダリングエンジン
- HTML、CSSを解析し、Webページを画面に描画
- JSエンジン
- JSコードを解析・実行する。
- ネットワーキングモジュール
- HTTP/HTTPS通信の処理を行う。
- キャッシュ管理やCookieの処理も担当する。
- データストレージ
- Cookie、ローカルストレージ、IndexedDBなどでユーザーデータを保存。
調べたところこのような感じとのことでした。
ブラウザの動作フロー
ユーザーがブラウザにURLを入力してからWebページが表示されるまでの流れは以下のとおりです。
- URLの解析
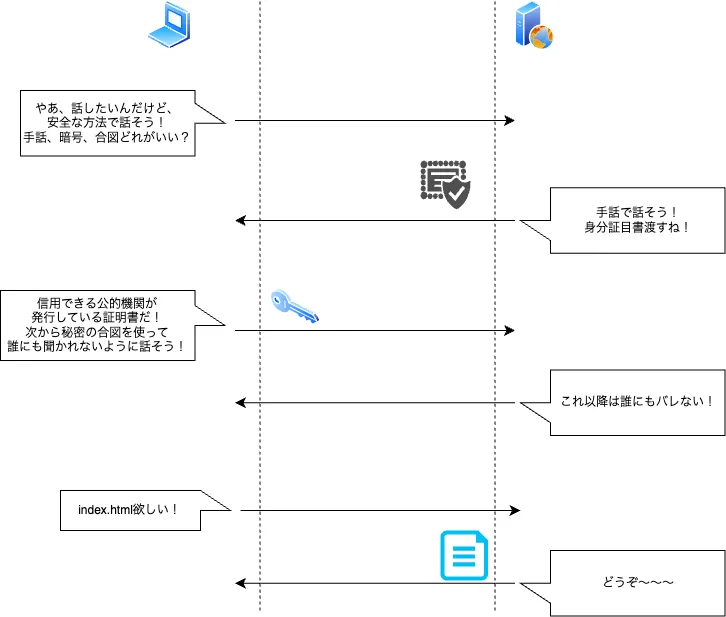
ユーザーが「https://blogs.abe-ichigo.dev」を入力すると
URLが有効か検証し、HTTPSであればSSL/TLSハンドシェイクが行われ、安全な通信が確立される。
ハンドシェイクを通して、クライアント(CL)とサーバー(SV)両者は暗号方式の合意、証明書の検証、鍵の共有を行い、その後の通信を暗号化する。
※下部に画像を作成してみました。 - DNS解決
URLのドメイン名をIPアドレスに変換する。
ブラウザ→OS→ルーター→DNSサーバーの順に問い合わせを行う。
例えば、yahoo.co.jpを183.79.250.251へ変換を行う。
ドメイン名はコンピューターは理解できないのでIPアドレスを取得している。 - TCP接続確立
DNSで取得したIPに対してTCP接続を確立する。(HTTPSの場合TLSハンドシェイクも実施) - HTTPリクエスト送信
ブラウザがSVにリクエストを送信する。 - SVがリクエストを返す
SVからHTMLが返ってくる。
- HTMLの解析 & DOMツリー生成
- トークン化
- パースツリー生成
- CSSOM生成
CSSファイルを読み込み、CSSOMツリーを生成。 - レイアウト計算
- DOMツリーとCSSOMツリーを統合してレンダーツリーを生成。
- 各要素の位置やサイズを計算。
- ペイント
ピクセル単位でレンダーツリーを描画。 - JSの実行
<script>タグを検出し、JSエンジンがスクリプトを実行。
DOM操作やイベント処理を行う。 - 画面への表示
全ての処理が完了し、ユーザーの画面にページが表示される。
HTMLトークン化
HTMLのトークン化 (HTML Tokenization) は、HTMLドキュメントを解析し、意味のある最小単位(トークン)に分割するプロセスです。
トークンの種類は以下のとおりでした。
- 開始タグトークン
例)<div>, <p>, <img> - 終了タグトークン
例)</div>, </p> - 自己終了タグトークン
例)<img />, <br /> - 属性トークン
タグ内の属性。
例)readonly - テキストトークン
タグ外のテキスト。例)Hello World - コメントトークン
例)<!-- コメント --> - DOCTYPEトークン
ドキュメントタイプ宣言。<!DOCTYPE html>
トークン化は、HTML文書を1文字ずつ読み取り、状態(属性など)からトークンを生成します。
その後、DOMツリー構築を行います。
次のようなHTMLであれば、トークンはこのようになるはず。
<!DOCTYPE html>
<html lang="ja">
<head>
<title>タイトル</title>
</head>
<body>
<h1 class="header">Hello, World!</h1>
<!-- コメントです -->
</body>
</html>DOCTYPE("html")
StartTag("html", attributes: { lang: "ja" })
StartTag("head")
StartTag("title")
Text("タイトル")
EndTag("title")
EndTag("head")
StartTag("body")
StartTag("h1", attributes: { class: "header" })
Text("Hello, World!")
EndTag("h1")
Comment(" コメントです ")
EndTag("body")
EndTag("html")DOMツリー
Document
├─ Doctype: html
└─ html (lang="ja")
├─ head
│ └─ title
│ └─ Text: "タイトル"
├─ body
│ ├─ h1 (class="header")
│ │ └─ Text: "Hello, World!"
│ └─ Comment: " コメントです "トークン化は予想ですが、正規表現で行われているかと思います。
下記のようなパタンで抽出可能かと思います。
改行がどのように処理されているかはいつか調べます。。。
コメント:<!--(.*)-->
ドキュメントタイプ:<!DOCTYPE\s+([^>]+)>
開始タグ:<([a-zA-Z0-9]+)([^>]*)>
終了タグ:</([a-zA-Z0-9]+)>
テキスト:>([^<]+)<
属性:([a-zA-Z-]+)="([^"]+)実際には状態マシンというものがあり、解析している中で今解析している文字はどのような状態にある時に読み取っているかを気にしているようでした。
具体的にはデータ状態、タグオープン状態、タグ名状態、属性状態があることでエラー耐性(閉じタグが抜けていても処理可能)があり、ストリーム処理(HTMLが全て読み込まれるまでに解析)を行うことができるとのことです。
DOMツリーはノードという表現をします。
上記のコードの例では、<h1>であればh1ノードであり、テキストを含みます。
この、DOMツリー化の目的は、JSから特定の要素へアクセスしコンテンツを動的に変更したり、レンダリングエンジンがDOMツリーを元にHTMLの表示を行っているためです。
さらに噛み砕くと
難しいのでさらに噛み砕いてみました。
トークン化は本の内容を単語ごとに分ける作業です。
「私はスーパーにいきます」といった単語は
私は | スーパー | に | いきます となります。
DOMツリー化は組み立て家具に例えられます。
トークン化により板やネジ、支柱などに分けられた部品は、決まりに従って組み立てることで家具が完成します。
JSエンジンの仕組み
JSエンジンは、コードの解析から実行まで以下の流れで処理します。
※この辺は他の言語にもある仕組みなので割愛します。
- パース
ソースコードをAST(抽象構文木)に変換。
コンピュータが実行可能な形に処理する工程。
※JS固有ではないため詳細は割愛します。
ESLintというツールがありますが、こちらはASTをを利用しています。潜在的なエラーやコーディング規約違反を検出しています。 - コンパイル
バイトコードへ変換
※JS固有ではないため詳細は割愛します。 - 最適化
実行中にJIT(Just-In-Time)コンパイル。
JITコンパイルは仮想マシン上で動作する言語(Java、C#など)やインタプリタ型言語(JS、Ruby、Pythonなど)で使用されます。
ソースコードを読み込み、逐次実行します。またホットコード(頻繁に実行されるコード)を特定し、JITコンパイラによって利用されます。
随時コンパイルを行い、その結果をもとに最適化を行います。
JITコンパイルは、binaryとなるため実行速度が向上したり、動的に最適化されたり、インタプリタ型言語でもコンパイル型言語に匹敵するパフォーマンスが実現されます。
一方で、初期のオーバーヘッドが発生するため初期実行が遅くなる可能性や、メモリ使用量の増加といったデメリットも挙げられます。
最適化手順としては、インライン化、ループの最適化・データキャッシュ最適化・分岐予測などが行われます。 - 実行
実際の処理を行い、DOM操作やイベントを処理する。
続きは次へ。。。

